Let me get to the formal stage of
how I put this in this hierarchical Bayesian
model . It's like
putting this grand coefficient framework -- it fits in really
easily. Through a judicious choice of stacking
my equations I can
have 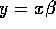 . So y is
going to be my log movement vector, x is going to be all these
covariants,
all the prices and promotional effects. Then I've got this
general error covariance matrix, and what I'm going to do
in the second stage is say that these
. So y is
going to be my log movement vector, x is going to be all these
covariants,
all the prices and promotional effects. Then I've got this
general error covariance matrix, and what I'm going to do
in the second stage is say that these 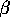 's from up
here, all these price coefficients, are now going to go to the
second stage of the model. I'm going to say that these store
parameters are related to the demographics and the competitive
characteristics and all the demographic data is in this z
matrix. On top of that I've got this relationship, with
these
's from up
here, all these price coefficients, are now going to go to the
second stage of the model. I'm going to say that these store
parameters are related to the demographics and the competitive
characteristics and all the demographic data is in this z
matrix. On top of that I've got this relationship, with
these 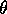 's which is essentially
what I've just showed you.
I'm going to take that
down into this third stage.
's which is essentially
what I've just showed you.
I'm going to take that
down into this third stage.
What's also going to be important is how similar are these
individual stores. How big is this random effect? So
I'm also going to have this 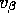 parameter and it's
going to go down here, because I've got to have a prior on where
in the store xxx is. The analyst has to provide this
x, y, z and w. The x is the pricing data, the
y is the
movement data, the z is the demographic data, and then down
here I've got to have another prior on what I expect the
relationships are going to be. I'm going to
be confused at this stage of this component about what are these
demographic relationships. Because I don't want to bias the
results, I don't want to say that I know that education
should have a positive relationship with price elasticity.
The next step is to say something about
what's my prior on the similarities across the stores. Now that
is going to be important. So I'm going to have to say something
about what is
parameter and it's
going to go down here, because I've got to have a prior on where
in the store xxx is. The analyst has to provide this
x, y, z and w. The x is the pricing data, the
y is the
movement data, the z is the demographic data, and then down
here I've got to have another prior on what I expect the
relationships are going to be. I'm going to
be confused at this stage of this component about what are these
demographic relationships. Because I don't want to bias the
results, I don't want to say that I know that education
should have a positive relationship with price elasticity.
The next step is to say something about
what's my prior on the similarities across the stores. Now that
is going to be important. So I'm going to have to say something
about what is 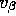 ?
?
For more detail click here.
 Previous Section
Previous Section
Next Section
Go to Table of Contents
Go to written version of paper