Comparison of Gibbs Sampler to Normal Approximation
The next thing I want to do is what's
happening -- suppose I looked at my estimator and
compared it to some kind of normal
approximation, just to see
whether it really is important to go through the Gibbs sampler.
Here I've just pulled out the old price
sensitivity parameter for Minute Maid and I'm looking at it from
the hyper-distribution, so I'm looking at this 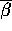 . So
when I have k=5 or when I've got a weaker prior,
the Gibbs estimate, the dashed line, and the normal
approximation are in agreement. When I start
decreasing my prior,
you start to see some
differences here. There's more kurtosis, it's
spread out more and then finally when I come down to
k=.1,
if I'm using the normal approximation,
I'm going to be quite poorly compared to a Gibbs estimate.
. So
when I have k=5 or when I've got a weaker prior,
the Gibbs estimate, the dashed line, and the normal
approximation are in agreement. When I start
decreasing my prior,
you start to see some
differences here. There's more kurtosis, it's
spread out more and then finally when I come down to
k=.1,
if I'm using the normal approximation,
I'm going to be quite poorly compared to a Gibbs estimate.
Click here to
see the marginal
posterior density for
hyper-distribution household value effect on premium own-price sensitivity.
 Previous Section
Previous Section
Next Section
Go to Table of Contents
Go to written version of paper