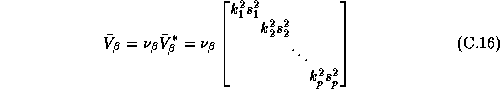
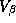 is to shrink our parameter estimates somewhere between the pooled and
individual LS estimates. For simplicity we set to
is to shrink our parameter estimates somewhere between the pooled and
individual LS estimates. For simplicity we set to 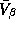 a
diagonal matrix. To allow for proper scaling of the different
coefficients we set the diagonal elements equal to the product of the
variance least squares estimates from the individual store models,
a
diagonal matrix. To allow for proper scaling of the different
coefficients we set the diagonal elements equal to the product of the
variance least squares estimates from the individual store models,
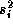 , and a scaling parameter,
, and a scaling parameter, 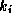 :
:
where p is the dimension of 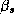 (or 192, i.e., 12
equations with 16 parameters each). We also set
(or 192, i.e., 12
equations with 16 parameters each). We also set 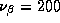 . The
relationship between
. The
relationship between 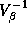 and
and 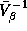 can be
seen by examining the mean and covariance matrix of this prior
distribution:
can be
seen by examining the mean and covariance matrix of this prior
distribution: 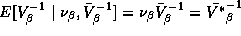 and
and 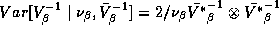 .
.