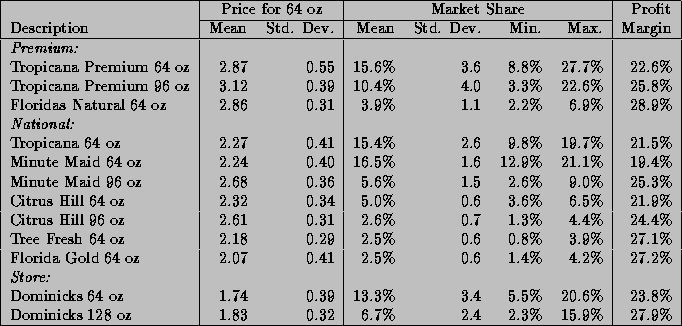
Table 1: Descriptive Statistics for Price, Market Share, and Profit Margins
The data used in this paper represents a unique single source dataset. Its uniqueness is a result of its size and the depth of information about movement, prices, promotion, profit margins, and competition. The data was collected from Dominick's Finer Foods (DFF) as part of the Micro-Marketing Project at the University of Chicago (Dreze, Hoch, and Purk 1993). DFF is a major supermarket chain in the Chicago metropolitan area with a 20% market share of supermarket sales. There are three different types of information used in this paper, each coming from different sources and discussed in the following sub-sections. The types of data collected here are readily available to supermarket retailers.
Store-Level Scanner Data: DFF provided weekly UPC-level scanner data for all 88 stores in the chain for up to three years. The scanner data includes unit sales, retail price, profit margin, and a deal-code. Out of these 88 stores, five have limited historical data, so we concentrate on the remaining 83 stores. To verify the correctness of the data, comparisons across stores and categories were made for each week. Certain weeks in which the integrity of the data was in doubt were removed from the sample. Also one brand was introduced in the early part of the data (Florida Gold), and another brand (Citrus Hill) is removed in the later part. Consequently we consider the middle 121 weeks of the sample period (June 1990 through October 1992), to avoid introduction and withdrawal effects.
There are 33 UPCs in the category. In order to a create a more manageable number of products we create twelve aggregates from the original UPC level data that have similar pricing and promotional strategies. The UPCs within a product aggregate differ only by flavoring, additives, or packaging (eg., regular, pulp, or calcium). The price of the aggregate is computed as a price index (i.e., an average weighted by market share) over all the UPCs that comprise the aggregate. The movement of the aggregate is computed as the sum of the movement (standardized to ounces). Prices within each aggregate are approximately proportional, therefore little pricing information is lost. Moreover we can still speak about profit maximization since we assume the relative prices of the items within an aggregate are fixed.
Summary statistics for average weekly prices, gross profits, and market shares across stores for the twelve aggregates are listed in Table 1. There is a natural division of products into three price-quality tiers: the premium brands (made from freshly squeezed oranges), the national brands (reconstituted from frozen orange juice concentrate), and the store brands (Dominick's private label). There is quite a bit of disparity in prices across the tiers, which leads to large differences in wholesale costs, even though the profit margins appear similar. An initial indication that store differences are present is the variation of market shares across stores. Dominick's 64 ounce OJ brand has an average market share of 13.3%, but the market shares across stores range anywhere from a minimum of 5.5% to a maximum of 20.6%.
Table 1: Descriptive Statistics for Price, Market Share, and Profit Margins
Promotional Data: Information about feature advertising in weekly newspaper fliers is provided by IRI's Infoscan, which provides an estimate of all commodity volume of a particular UPC that received feature advertisement. IRI collects this data based on a representative sample of approximately 60 stores from throughout the Chicago metropolitan area. The information provided was at an aggregate level for the Dominick's chain and for all other competitors. The aggregation of the competitor information reduces its value for our purposes and is not used. In-store promotion is measured using a deal code provided in DFF's store-level scanner database. The deal-code is a dummy variable which shows whether there was a bonus-buy sticker on the shelf or an in-store coupon. Since these promotional variables are at the UPC level, we create indices of the feature and deal variables for each aggregate similarly to that of price.
Store Trading Area Data (Competitive/Demographic Characteristics): Market Metrics, a leading firm in the use of demographic data, used block level data from the U.S. Census to compute a store's trading area. A store's trading area refers to a geographical area around the store. It is calculated by finding the number of people needed to sustain a given level of sales for this area. Geographical boundaries (such as roads, railroad tracks, rivers, etc.) are considered when this trading area is formed. The demographic composition of the store's trading area is computed by summing up the assigned proportion of each of the U.S. Census blocks within the prescribed trading area.
The selection of variables is guided by a household production framework. For a further discussion of variable selection issues refer to Hoch et al. (1995). A total of eleven demographic and competitive variables are used to characterize a store's trading area. These variables summarize all the major categories of information that are available. Table 2 lists each variable along with their descriptive statistics. The statistics in the table are generated for the 83 stores in our sample. Four of the demographic variables measure general consumer characteristics: the percentage of the population over age 60 (Elderly), percentage of the population that has a college degree (Educ), the percentage of black and Hispanic persons (Ethnic), and the percentage of households with five or more members (Fam-size). The other demographic variables are: log of median income (Income), the percentage of homes with a value greater than $150,000 (House-val), and the percentage of women who work (Work-wom).
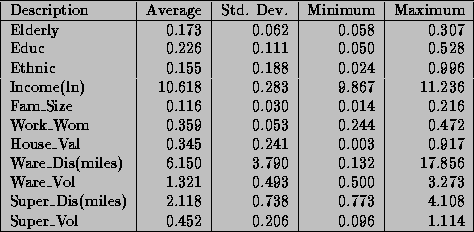
Table 2: Descriptive Statistics for Demographic/Competitive Variables Across Stores
The other four variables measure the competitive environment of the store's trading area. There are two broad types of stores for which we have information: warehouse and supermarkets. The warehouse stores are larger and use an everyday low pricing strategy (EDLP). Other supermarket stores use a high-low pricing strategy (Hi-Lo) similar to Dominick's. We have broken out competitive effects between these two groups since we expect that these two pricing strategies will have different effects. For each group we use two measures of competition: distance (in miles) and relative volume. Distance is doubled in urban areas to reflect poorer driving conditions, which approximates Market Metrics measure of driving times. Relative volume is the ratio of sales in the competitor to that of the Dominick's store. The warehouse competitor variables are computed with respect to the nearest warehouse store, and the supermarket competitor variables use an average of the nearest five competitors.
 Back
Back