A Bayesian Approach
- Random coefficient model that relates the parameters to
characteristics of the store's trading area.
- exploit store commonalities
- allow for store heterogeneity
From the Bayesian perspective what's going to be
good is to say, look, each of these stores does have some unique
characteristics, but all these stores have something in common.
They're all coming from the same chain, they're all in the same
general area, they're all dealing with consumers that are
exposed to the same types of advertisements over time, so it
makes a lot of sense to say that what's going on here is
probably some kind of random coefficient model. And what I'm
going to do is I'm going to incorporate this demographic
information at this stage of the model, so I'm going to say that
look, I'm going to go out and take micro-efficient so let's go
out, I've got all the parameters from this model that I just
gave, I've got this 192 parameters let's just go out and think
about one element from this cross-price elasticity matrix. So
let's pull out, like cross-pricing or the cross price elasticity
of Minute Maid orange juice. So in this case, what I'm going to
say is that this co-efficient is 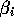 's for an individual store and
it's going to equal to some cost-effect across the stores, plus
some kind of demographic effect, plus some type of random
effect. Click here to see the mathematical form.
So, in this case, you know, this random effect is
really, you know, I'm going to go back to these individual store
models, or something similar to it. If the demographic effect is strong
and there's not a lot of random error here, it's going to look
something like a fixed effects model. Or if the demographic
effects are nil, and there's not a lot of random error variage
across these parameters, then I'm going to back to this xx model
case. The point is I'm trying to be inclusive of this, because I
don't know exactly how strong these relationships are, for all
the reasons I've just stated.
's for an individual store and
it's going to equal to some cost-effect across the stores, plus
some kind of demographic effect, plus some type of random
effect. Click here to see the mathematical form.
So, in this case, you know, this random effect is
really, you know, I'm going to go back to these individual store
models, or something similar to it. If the demographic effect is strong
and there's not a lot of random error here, it's going to look
something like a fixed effects model. Or if the demographic
effects are nil, and there's not a lot of random error variage
across these parameters, then I'm going to back to this xx model
case. The point is I'm trying to be inclusive of this, because I
don't know exactly how strong these relationships are, for all
the reasons I've just stated.
Back