Abstract
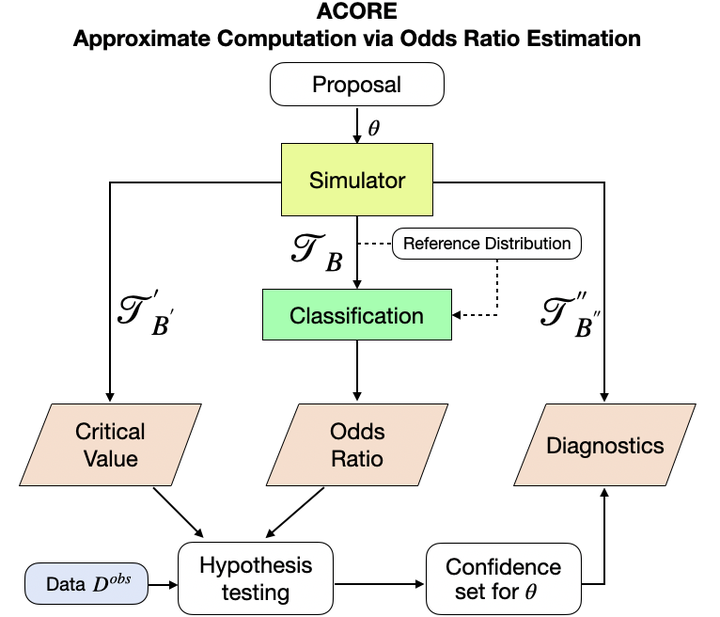
Parameter estimation, statistical tests and confidence sets are the cornerstones of classical statistics that allow scientists to make inferences about the underlying process that generated the observed data. A key question is whether one can still construct hypothesis tests and confidence sets with proper coverage and high power in a so-called likelihood-free inference (LFI) setting; that is, a setting where the likelihood is not explicitly known but one can forward-simulate observable data according to a stochastic model. In this paper, we present 𝙰𝙲𝙾𝚁𝙴 (Approximate Computation via Odds Ratio Estimation), a frequentist approach to LFI that first formulates the classical likelihood ratio test (LRT) as a parametrized classification problem, and then uses the equivalence of tests and confidence sets to build confidence regions for parameters of interest. We also present a goodness-of-fit procedure for checking whether the constructed tests and confidence regions are valid. 𝙰𝙲𝙾𝚁𝙴 is based on the key observation that the LRT statistic, the rejection probability of the test, and the coverage of the confidence set are conditional distribution functions which often vary smoothly as a function of the parameters of interest. Hence, instead of relying solely on samples simulated at fixed parameter settings (as is the convention in standard Monte Carlo solutions), one can leverage machine learning tools and data simulated in the neighborhood of a parameter to improve estimates of quantities of interest. We demonstrate the efficacy of 𝙰𝙲𝙾𝚁𝙴 with both theoretical and empirical results. Our implementation is available on Github.